
Scaling Hackathon Judging with Multi-Agent Evaluation at Chai Code
How we built an agentic pipeline that evaluates 200+ project submissions in under 4 hours, with detailed feedback for every participant
At Chai Code, we are building a public hackathon platform where submissions are evaluated fairly at any scale. As we get closer to launch, we needed to validate the evaluation pipeline on real projects with real stakes. Our internal cohort buildathons provided the testing ground.
A recent buildathon had over 200 submissions. Judging them manually would take weeks. We needed results in hours, with detailed feedback for every participant, not just the winners.
This post covers the system we built and how it performed across multiple evaluation runs.
The problem
Hackathon judging breaks down in predictable ways.

Volume degrades quality. A judge reviewing submission #150 is not reading code with the same attention as submission #5. They skim the README, click the demo link, and score based on surface impressions.
Surface beats substance. We've watched projects with no authentication, no database, and no meaningful backend win because the landing page looked polished. Meanwhile, well-architected submissions with proper engineering lost because nobody had time to read the code.
No feedback loop. Participants who don't win learn nothing. They don't know if their code was bad, their idea was weak, or their deployment was broken. There's no growth signal.
Results take too long. By the time winners are announced weeks later, participants have moved on. The momentum is gone.
Architecture
We built a multi-agent evaluation pipeline. Each submission goes through multiple stages of analysis, across multiple models, before a human reviewer makes the final call.

The architecture is queue-based and checkpoint-driven. Every submission enters a processing queue, and the system checkpoints after each individual evaluation. If the server crashes at submission #147 out of 5,000, it resumes at #148. No work is ever lost.
This is what makes it scale. The same pipeline that handles 20 submissions handles 5,000. The queue processes them sequentially or in parallel, checkpointing each result to disk.
Agent swarm
For each submission, an orchestrator spawns a swarm of specialized agents. Each agent is responsible for a different dimension of evaluation, and they share context with each other through a memory layer that persists across the entire run.
The agents don't just skim your README. They read source files, verify deployment URLs, distinguish between real logic and scaffolded boilerplate, and cross-reference claims against actual code.
Every score maps to specific files in the repository. Nothing is abstract.
Relative scoring
Submissions are not scored in isolation. The agent swarm maintains a shared memory across the entire evaluation run. Each judgment feeds context back into the next, so the system's understanding of the cohort sharpens with every submission it processes.

When the agent evaluates submission #150, it has the full picture of what "good API integration" looks like across the cohort. This prevents score inflation and ensures consistency that a single human judge reviewing hundreds of projects could never maintain.
Multiple models, multiple rounds
The pipeline supports different models at different stages. Which model handles initial evaluation, which handles the final comparative round ...that's configurable per deployment and per hackathon. The system is model-agnostic by design.
The final round is structurally different from the initial pass. Top candidates are loaded into a single context and compared head-to-head, with the ability to adjust individual scores based on the full picture. This layered approach catches what a single pass would miss.
Human review
AI cannot be the final arbiter. What it can do is surface evidence at scale.
Every score the system produces links to specific code, specific files, specific deployment checks. The human reviewer isn't re-reading 200 repositories. They're verifying that the AI's reasoning holds. If it doesn't, they override.
This is the key insight: the system doesn't replace human judgment. It compresses weeks of manual review into hours of focused verification.
Results
We've run this system across multiple internal buildathons.
Our largest evaluation processed over 200 submissions in under 4 hours. Every participant received per-criterion scores with file-level references explaining why they scored the way they did.
A separate batch of 20 React Native submissions was evaluated and ranked within an hour. Hackathons that previously required weeks of manual review were completed in a single session.
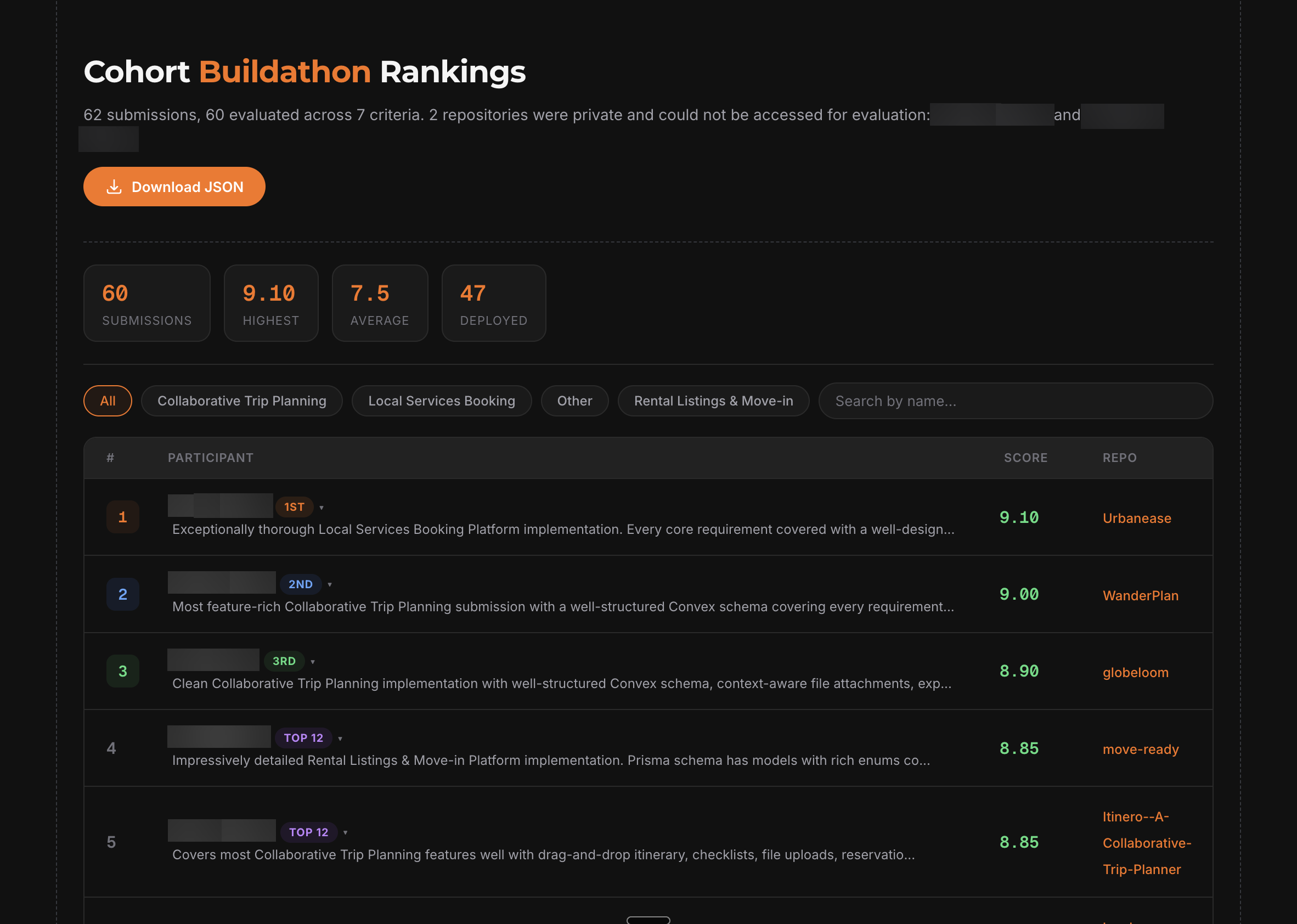
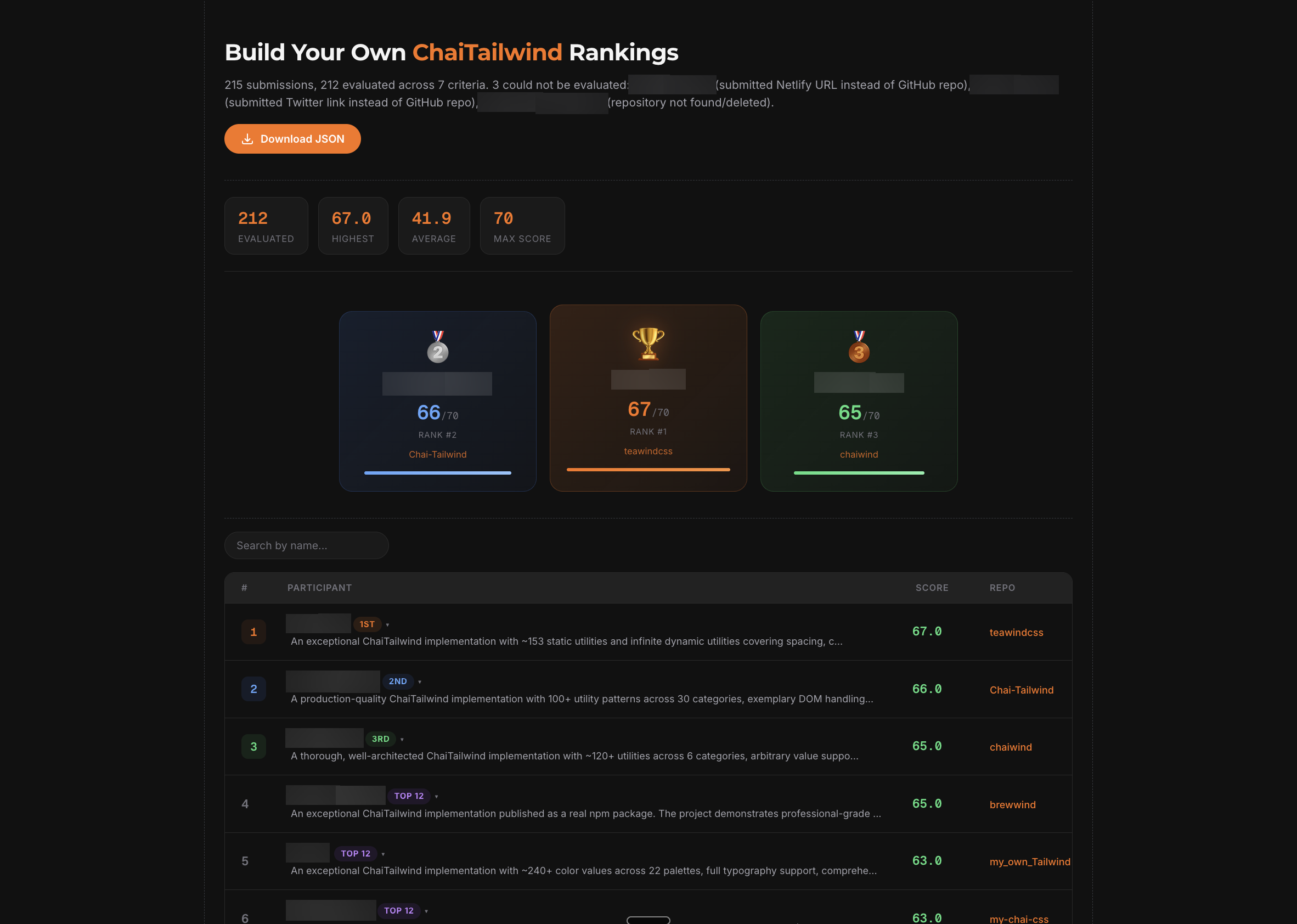
Participant names blurred for privacy. Every participant receives a ranking, a score, and a written summary explaining what they did well and what to improve ...not just the winners.
Scale
The architecture is queue-based with checkpointing after every single evaluation. There is no theoretical upper limit on the number of submissions. 200+ is what we've processed so far, but the same pipeline handles 2,000 or 10,000 submissions without any architectural changes. Most hackathons top out at 1,000–2,000 submissions ...this system covers every practical scenario.
If the server crashes at submission #4,847 out of 5,000, it resumes at #4,848. No work is ever lost.
Continuous refinement
The pipeline isn't static. Every run teaches us where the scoring drifts and we tighten it. We review edge cases, adjust how agents weigh evidence, and sharpen the calibration so scores reflect actual quality more accurately each time.
The system that judges hackathon #5 will be measurably sharper than the one that judged hackathon #1.
What's next
This system is currently in internal use across Chai Code's cohort buildathons. We're preparing to deploy it for public hackathons with significant prize pools, where speed, fairness, and transparency matter even more.
The same evaluation pipeline, the same per-participant feedback, the same ranking system ...but open to everyone. Public hackathons on Chai Code, coming soon.
The goal is straightforward: every participant should know exactly where they stand and why. Not just winners. Everyone.
Built at Chai Code by Aryan Kumar.
Comments (0)
Loading comments...