
Building CandidAI: An AI Interviewer That Actually Sees You
How I built a real-time AI technical interviewer using Vision Agents SDK that watches body language, evaluates live code, and generates comprehensive interview reports - all over WebRTC
Building CandidAI: An AI Interviewer That Actually Sees You
How I built a real-time AI technical interviewer that watches your body language, listens to your answers, evaluates your code, and generates a full performance report - in one week.
"What if your mock interviewer could actually see you fidgeting, notice when you're confused, and adapt in real-time?"
When the Vision Possible: Agent Protocol hackathon dropped, the brief was clear: build multi-modal AI agents that watch, listen, and understand video in real-time. Most people went for security cameras or sports coaching. I went for something that every developer dreads - technical interviews.
![]()
The hackathon was sponsored by Vision Agents - Stream's open-source SDK for building real-time Vision AI agents. It gives you WebRTC transport, video frame capture, event systems, and native LLM APIs out of the box. The challenge: use it to build something that pushes the boundaries of real-time video intelligence.
The Problem
Technical interviews are broken. Companies spend thousands on hiring pipelines, candidates spend weeks grinding LeetCode, and at the end of it all, the evaluation is still subjective. A human interviewer might miss that the candidate's hands were shaking, or that they solved the problem in half the expected time but stumbled on communication.
What if we could build an interviewer that never misses a signal?
CandidAI: The Idea
CandidAI is a full-stack AI technical interviewer that:
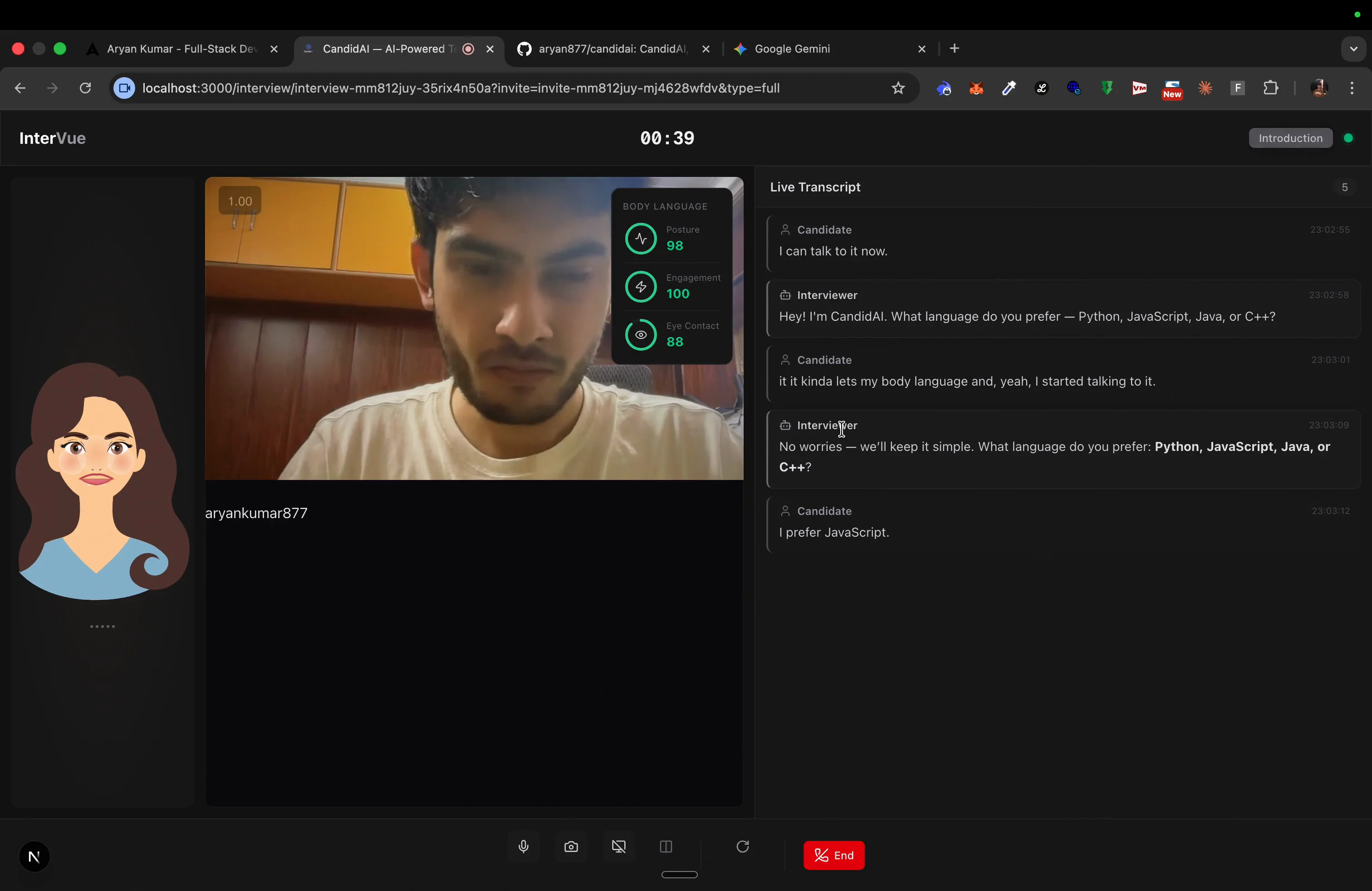
- Sees you - YOLO pose estimation tracks body language every 3 seconds (posture, fidgeting, eye contact)
- Hears you - Deepgram STT transcribes speech in real-time with smart turn detection
- Tests you - Presents coding challenges with a Monaco editor, evaluates solutions, asks MCQs
- Talks to you - Edge TTS gives the AI a natural voice over WebRTC
- Knows the material - PostgreSQL + pgvector RAG over 169 interview question files
- Reports everything - Generates radar charts, timelines, and dimensional scores after each session

The Architecture
Here's where it gets interesting. The entire system runs over WebRTC using Stream's Vision Agents SDK:
Browser (Next.js) <--WebRTC (Stream)--> Python Agent (Vision Agents SDK)
| |
|-- Convex Cloud (DB) |-- OpenAI GPT-5.2 (LLM)
|-- Monaco Editor |-- PostgreSQL + pgvector (RAG)
|-- SVG Avatar (Framer Motion) |-- Deepgram STT
|-- Recharts (reports) |-- Edge TTS (free)
|-- YOLO Pose (yolo11n-pose.pt)
The agent joins the call as a WebRTC participant - it receives the candidate's audio and video tracks through Stream's SFU (Selective Forwarding Unit), processes them through the AI pipeline, and sends back audio + custom events.
Vision Pipeline (The Core of It)
This is where Vision Agents SDK shines. When the candidate joins:
- Continuous capture: 1 FPS from the active video track (webcam or screen share)
- Frame buffer: 5-second rolling buffer = ~5 frames
- Send trigger: When Deepgram detects the user finished speaking
- To the LLM: Last 5 buffered frames sent as base64 JPEGs with conversation context
- Screen share priority: When the candidate shares their screen, the SDK automatically switches from webcam to screen share (priority=1 vs 0)
# The agent factory wires everything together
agent = CandidAIAgent(
llm=openrouter_vlm, # GPT-5.2 with vision (frame buffering + tool calling)
stt=deepgram_stt, # Real-time transcription
tts=edge_tts, # Free Microsoft neural voice
transport=stream_edge, # WebRTC via Stream
processors=[pose_processor] # YOLO body language
)
Body Language Analysis
Every 3 seconds, the YOLO pose processor analyzes the candidate's webcam feed:
# Pose processor emits events with body language metrics
class BodyLanguageEvent:
posture: float # 0-1 score
fidgeting: float # 0-1 score
eye_contact: float # 0-1 score
These metrics stream to the frontend as custom events through Stream's SFU - the browser never talks to the AI pipeline directly. Everything flows through WebRTC.
10 Function Tools
The LLM doesn't just talk - it acts. I gave it 10 function tools:
| Tool | What It Does |
|---|---|
search_knowledge_base | Queries pgvector RAG for relevant interview questions |
set_expression | Controls the SVG avatar's face (10 expressions) |
nod_head | Avatar nods in agreement |
raise_eyebrows | Avatar shows surprise |
score_response | Scores candidate on 5 dimensions (0-10) |
present_mcq | Shows multiple choice questions |
present_coding_challenge | Opens Monaco editor with a problem |
evaluate_code | Reviews submitted code |
transition_phase | Moves through interview phases |
generate_report | Creates the final assessment |
The Data Flow

The frontend is built with Next.js 15, React 19, and Tailwind v4. The interview room has:
- Animated SVG avatar - 12 animatable properties (eyebrows, pupils, mouth, head tilt, cheek blush) driven by Framer Motion with lerp interpolation
- Monaco code editor - Full syntax highlighting with a custom dark theme
- Real-time transcript - Shows the conversation as it happens
- Body language indicator - Visual feedback on posture, fidgeting, eye contact
- MCQ cards - For quick technical knowledge checks
The avatar is the star. Each expression defines 12 properties - when the LLM calls set_expression("thinking"), the custom event flows through WebRTC → useAvatarEvents hook → lerp interpolation smoothly transitions all 12 properties. It feels alive.
The RAG Knowledge Base
I didn't want the interviewer to ask generic questions. So I built a RAG system over 169 curated markdown files covering:
- Behavioral questions with rubrics and senior-level variants
- Coding problems across 17 categories (arrays, graphs, DP, trees...)
- System design (Twitter, web crawler, scaling AWS...)
- Frontend deep-dives (company-specific questions from Meta, Google, Amazon...)
- Technical concepts (closures, event delegation, virtual DOM, CORS...)
PostgreSQL + pgvector with fastembed (BAAI/bge-small-en-v1.5) handles the embeddings. The agent queries relevant questions based on the interview context.
Five-Phase Interview Flow
The interview follows a structured 5-phase flow:
- Intro - Quick greeting, language preference
- Behavioral - STAR-method questions, scored on communication
- Technical - Deep-dive concepts, MCQs
- Coding - Live coding challenge with real-time evaluation
- Wrapup - Final report generation with radar chart
Each phase transition is a function call from the LLM. The agent decides when to move on based on the conversation flow.
How I Used Vision Agents SDK
Vision Agents SDK was the backbone of this project. Here's specifically what it provided:
getstream.Edge()transport - WebRTC connection through Stream's SFU with sub-30ms audio/video latency- Video track subscription - Automatic capture of webcam and screen share at 1 FPS with priority-based switching
VideoProcessorbase class - Extended for YOLO pose estimation with theWarmablepattern for model loadingAgentclass - Core agent lifecycle with function tool registration via@llm.register_functionEventManager- Custom event system for body language metrics, avatar control, and scoressend_custom_event()- Bidirectional communication between agent and frontend through Stream's SFU- Native LLM integration - OpenAI GPT-5.2 VLM with vision (sends buffered frames as base64 JPEGs + tool calling)
- STT/TTS pipeline - Deepgram transcription + Edge TTS with smart turn detection
Without Vision Agents, I would have had to build the entire WebRTC pipeline, video frame capture, audio routing, and event system from scratch. The SDK handled all of that, letting me focus on the interview logic.
Bugs That Nearly Killed Me
1. The Silent Video Track Bug
The YOLO pose processor wasn't receiving any frames. Turns out, the SDK's EventManager.subscribe() uses typing.get_type_hints() to route events. My event handler was missing a type hint:
# BROKEN - handler never registered
async def _on_track_published(self, event):
...
# FIXED - SDK can now route the event
async def _on_track_published(self, event: TrackPublishedEvent):
...
One missing type hint = complete silence. Took me hours to figure out.
2. OpenAI API SSL Errors
Sending 5 base64 images per LLM call over a long-running connection caused transient SSL errors (SSLV3_ALERT_BAD_RECORD_MAC). Fixed with retry logic - 3 attempts with exponential backoff.
The Stack
| Layer | Technology |
|---|---|
| LLM | OpenAI GPT-5.2 (vision + function calling) |
| STT | Deepgram (flux-general-en) |
| TTS | Edge TTS (free Microsoft neural, en-US-AriaNeural) |
| Pose | YOLO 11n-pose via Ultralytics |
| Transport | Vision Agents SDK + Stream (WebRTC) |
| Frontend | Next.js 15 + React 19 + Tailwind v4 |
| Database | Convex Cloud (7 tables) |
| RAG | PostgreSQL + pgvector + fastembed |
| Editor | Monaco (@monaco-editor/react) |
| Charts | Recharts (RadarChart) |
| Deploy | Docker Compose |
What I Learned
Building CandidAI in a week pushed me to my limits. Some takeaways:
-
Vision Agents SDK is genuinely powerful - The amount of infrastructure it abstracts away (WebRTC, SFU, video capture, event routing) is massive. I went from zero to a working real-time video AI agent in days.
-
Type hints matter in event-driven systems - The SDK uses runtime type introspection for event routing. Miss a hint, lose an event. Document your types.
-
Real-time AI is about buffering, not streaming - You don't send every frame to the LLM. You buffer, sample, and send snapshots at the right moment (when the user finishes speaking).
-
Custom events over WebRTC are underrated - Stream's
send_custom_event()let me build an entire UI control protocol (avatar expressions, scores, phases, challenges) without any additional WebSocket connections. -
Body language adds a dimension - Even basic posture/fidgeting/eye-contact scores provide surprisingly useful interview insights. The radar chart at the end tells a story that transcripts alone can't.
Try It
CandidAI is open source. Clone it, set up your API keys, and run your own AI technical interviews:
git clone https://github.com/aryan877/candidai.git
cd candidai
docker compose - f docker-compose.dev.yml up
The AI will greet you, ask your preferred language, and take you through a full 5-phase technical interview - behavioral, technical deep-dive, live coding, and a final report with dimensional scores.
Built for the Vision Possible: Agent Protocol hackathon. Powered by Vision Agents SDK by Stream.
Comments (0)
Loading comments...